AImotive的aiWare4 NPU内核为5nm和3nm芯片的汽车和边缘AI应用增加了波前存储器处理、升级的安全性和低功耗功能
匈牙利领先的人工智能技术开发商AImotive开发了下一代神经网络处理单元(NPU)设计,性能比以前的设计提高了一倍。
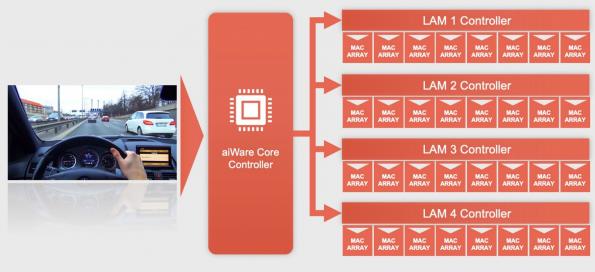
第四代aiWare automotive NPU硬件IP以2GHz的频率为每个核心提供多达64个TOP,是以前设计的两倍。它处理多达16384个INT8操作,内部精度为32位。它的目标是基于5nm和3nm工艺技术的芯片设计。该公司与台湾芯片制造商NextChip有着重要的合作关系。
以ISO26262 ASIL-B安全支持为标准,电源性能得到了改善。ASIL-D具有可配置的安全机制,实现了硅开销与功能安全要求和目标之间的平衡。
每个核可扩展到64个top,每个多核集群最多256个top,具有更大的片上内存配置能力,硬件安全机制和外部/共享内存支持
增强的标准硬件功能和相关文档,确保直接符合ISO26262 ASIL B和更高的符合SEooC(安全元素脱离上下文)和上下文安全元素应用程序。
核心展示了典型CNN神经网络框架的8-10个有效TOPS/W,使用5nm或更小的过程节点,理论峰值高达30个TOPS/W。AImotive说,对于更广泛的CNN拓扑,尤其是流行的vgg16和Yolo图像框架,核心的效率高达98%。这在aiWare3和NextChip上显示。
这种效率来自于MAC阵列,它在不使用矩阵乘法器的情况下,对2D和3D卷积和反卷积进行了优化。它还使用了一种新的存储架构,称为波前RAM (WFRAM),具有交叉多任务调度算法。这是一种为GPU数据处理而开发的技术,可以实现更多的并行执行,并提高多任务处理能力。与aiWare3相比,它大大减少了需要访问大量外部内存资源的cnn的内存带宽。
这种组合使aiWare4能够执行广泛的CNN





